Method Overview
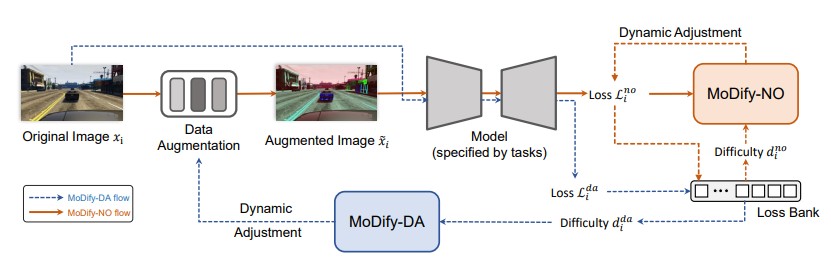
Overall architecture of the proposed Momentum Difficulty (MoDify). In the MoDify-DA flow (highlighted by blue arrows), the network takes the original image as input and generates its loss, and applies the loss to compute the difficulty level with the Loss Bank. MoDify-DA dynamically adjusts the strength of data augmentation. In the MoDify-NO flow (highlighted by red arrows), the network takes the augmented image as input. Then the difficulty degree of the augmented image is calculated in the same way. MoDify-NO decides whether postpone, drop, or learn from this sample. Noted the sample is fed for training only if its difficulty level is aligned with the model's capability. Additionally, MoDify-DA introduces little computational overhead without involving any back propagation.